2022. 7. 21. 22:57ㆍMachine Learning
머신러닝에서 분류 모델에 대한 평가 지표로 자주 활용되는 지표로 ROC-AUC, PR-AUC가 있다.
이진 분류 모델의 경우 0에서 1사이의 확률값을 예측한 뒤 임계값 (Threshold) 을 기준으로 0, 1을 분류한다. 대부분의 불균형 데이터에서 모델의 정확도 (Accuracy) 뿐만 아니라, 임계값에 따른 정밀도 (Precision) 와 재현율 (Recall) 의 상충관계를 고려하여 최적의 임계값을 결정하게 된다. 이때 특정 임계값에 영향을 받지 않고, 모델 간의 성능을 비교하기 위해 ROC-AUC 및 PR-AUC 지표가 활용된다.
1. Confusion matrix (혼동 행렬)
우선 분류의 평가지표를 계산하기 위한 기초가 되는 Confusion matix의 구성을 살펴보자.
| 실제 값 (Actual) | |||
| Negative (0) | Positive (1) | ||
| 예측 값 (Predicted) |
Negative (0) | TN (True Negative) | FN (False Negative) |
| Positive (1) | FP (False Positive) | TP (True Positive) | |
개인적으로 FN과 FP는 자주 헷갈리는 용어인데 예측값을 기준으로 Positive 와 Negative 가 결정된다고 생각하자. 즉, FP는 모델이 양성 (Positive) 이라고 예측했지만, 사실은 잘못된 가짜 양성 (False Positive) 인 것이다. (FN 의 경우 동일한 방식으로 해석하면 된다.)
2. TPR과 FPR, Recall과 Precision
다음은 ROC-AUC와 PR-AUC에서 사용되는 4가지 지표(사실은 3가지, TPR=Recall) 의 공식을 혼동행렬을 기반으로 살펴보자.
2.1. TPR (True Positive Rate, Recall or Sensitivity)
- TPR = TP / (TP+FN)
실제 Positive 샘플 (TP+FN) 중 Positive (TP)로 올바르게 예측한 비율을 의미한다. 해당 지표는 실제 Positive를 Negative로 잘못 예측했을 때의 리스크가 더 큰 업무에서 중요하게 여겨진다 (즉, FN의 리스크 > FP의 리스크). 예를 들면, 금융권의 사기 거래 탐지, 연체/부도 예측 등이 있다.
2.2. FPR (False Positive Rate or False Alarm Rate)
- FPR = FP / (FP+TN)
실제 Negative 샘플 (FP+TN) 중 Positive (FP)로 잘못 예측한 비율을 의미한다. 해당 지표는 모델의 오차이며, 정상 샘플을 이상 샘플로 잘못 예측함으로써 조치 및 기회 비용이 발생하므로 업무에 따라 허용할 수 있는 오차 범위를 결정하는 데 관여한다.
2.3. Precision
- Precision = TP / (FP+TP)
Positive 로 예측한 샘플 (FP+TP) 중 실제 Positive 샘플의 비율을 의미한다. 해당 지표는 Positive 예측의 정확도를 의미한다고 할 수 있다.
3. ROC-AUC vs PR-AUC
3.1. 비교
| ROC-AUC | PR-AUC | |
| x 축 | FPR | Recall (TPR) |
| y 축 | TPR | Precision |
| 좋은 모델 | FPR 낮을수록, TPR 높을수록 (곡선이 왼쪽, 위로 향할수록) |
Recall 높을수록, Precision 높을수록 (곡선이 오른쪽, 위로 향할수록) |
3.2. 설명
우선 AUC 는 Area Under Curve 의 약자로 그래프의 곡선 아래 면적을 의미한다. ROC 는 Receiver Operating Characteristic 의 약자로 임계값에 따른 FPR-TPR curve를 나타낸다. PR 은 Precision Recall 의 약자로 이름 그대로 임계값에 따른 Precision-Recall curve를 나타낸다. (임계값은 0 ~ 1 사이의 확률값을 가진다.)

ROC, PR curve를 살펴보기 위해 위와 같이 임의로 불균형 데이터 샘플을 생성하였다 (Positive:Negative = 1,000:10,000). 이때, threshold를 0부터 0.01간격으로 증가시키면서 confusion matrix 및 각 curve 생성에 필요한 성능지표들을 계산하였다.
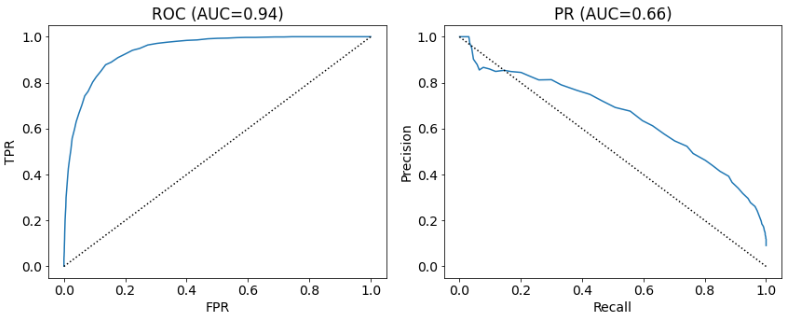
그 결과를 위 그래프와 같이 ROC, PR curve로 나타내고, 그래프 아래 면적(AUC) 값을 계산하였다. 아래에서 두 그래프의 특징에 대해 자세히 살펴보자.
3.2.1. ROC-AUC

ROC 곡선을 보면 (0, 0)에서 (1, 1)을 연결하는 곡선으로 왼쪽 위로 볼록한 모양으로 나타난다. 랜덤하게 예측할 경우는 직선에 수렴하고, AUC는 0.5에 근사하는 값을 가진다. 따라서, 랜덤한 예측 모델이 아니라면 ROC-AUC가 0.5 초과 1이하의 값을 가진다.
임계값이 0에 가까울수록 1로 예측하는 건수가 많아짐으로 0을 잘못 예측한 오차비율(FPR)은 높아지고, 1을 잘 예측한 비율(TPR)도 높아진다. 반대로 임계값이 1에 가까울수록 0으로 예측하는 건수가 많아지면서, FPR과 TPR은 0으로 수렴하게 된다.
임계값을 일정하기 증가/감소시킴에 따라, FPR, TPR의 감소/증가하는 속도가 동일한 크기를 나타내지 않으므로 볼록한 곡선 형태로 나타난다. 즉, 임계값을 0부터 증가시키면 처음에는 FPR이 빠르게 감소하고, 최적의 지점을 지나면 TPR이 빠르게 감소하게 된다.
3.2.2. PR-AUC

PR 곡선을 보면 (0, 1)에서 (1, 0) 사이의 곡선으로 오른쪽 위로 볼록한 모양으로 나타난다.PR 곡선은 ROC 곡선과 같이 매끄러운 형태가 아니다. 랜덤한 예측 모델이라고 해서 대각선 형태의 그래프롤 가지는 것도 아니다. 오히려 랜덤한 모델의 경우 Precision이 일정한 값을 가져서 가로선 형태로 나타날 것이다.
PR 곡선은 ROC 곡선의 한계점을 극복하고자 FPR이 아닌 Precision을 도입하였다. Recall(TPR)이 실제 1의 정확도라면 Precision은 예측(1)의 정확도를 의미한다. 임계값이 0에 가까울수록 Recall은 높아지지만, 0의 오차 건수가 동시에 많아지므로 Precision은 낮아진다. 반대로 임계값이 1에 가까워지면 Recall은 낮아지지만, Precision은 높아진다. 이처럼 두 지표의 상충관계에 의해 그래프는 감소하는 형태를 띄게 된다.
처음 공부할 때는 ROC-AUC를 먼저 배우고, 일반적으로 AUC라고 하면 ROC-AUC를 의미하여 익숙하다. 하지만 실제 업무에서는 Precision, Recall을 고려하면서 모형을 개발하는 경우가 더 많다. ROC의 경우 이름에서 그 의미가 와닿지 않아서 2개의 축을 나타내는 지표(FPR, TPR)를 매번 다시 찾아서 확인했다. 그래서 이번 기회에 확실히 정리해보고자 이 글을 작성하게 되었다.
4. 참고
'Machine Learning' 카테고리의 다른 글
| ChatGPT란? (개념 및 원리) (1) | 2023.04.14 |
|---|---|
| 공부 기록 1일. AutoML 도입 효과 및 학습 목적 (0) | 2023.02.16 |
| NLP 실습 - (2) BERT 모델 학습 (0) | 2023.02.02 |
| NLP 실습 - (1) 데이터 수집 및 전처리 (1) | 2023.01.29 |
| AutoML 이란? (종류 및 장단점) (0) | 2022.11.21 |